Comment j'ai construit mon deuxième cerveau IA avec Obsidian et Claude Code
Une méthode simple pour que ton IA arrête d'oublier et garde en mémoire tout ce que tu lui apprends, grâce à Obsidian et Claude Code.
TutorielClaude

Une méthode simple pour que ton IA arrête d'oublier et garde en mémoire tout ce que tu lui apprends, grâce à Obsidian et Claude Code.

Tu utilises ton IA comme un moteur de recherche qui oublie tout entre deux phrases. Tu lui expliques ton projet, tes choix techniques, ta façon de travailler. Elle suit parfaitement. Et le lendemain ? Page blanche. Tu recommences depuis zéro, encore et encore.
Le réflexe, c'est d'accuser sa mémoire. Mais le vrai problème n'est pas là : ce n'est pas un problème de mémoire, c'est un problème de système. Ton IA n'a nulle part où ranger ce qu'elle apprend. Alors tout s'évapore à la fermeture de la fenêtre.
Les solutions toutes faites n'y changent rien. La mémoire de ChatGPT, les Claude Projects, les custom GPTs : à chaque question, ils relisent tes documents en vitesse et improvisent une réponse, au lieu de retenir pour de bon.
Dans cet article, je te montre comment casser ce cycle. Tu vas construire un deuxième cerveau avec Obsidian et Claude Code : un espace où ton IA range ce qu'elle apprend sous forme de fiches, le garde pour de bon, et relie chaque idée aux autres. Plus tu l'utilises, plus il devient intelligent, l'inverse exact d'une conversation jetable.
Un deuxième cerveau, c'est simplement un dossier sur ton ordinateur où ton IA stocke ses connaissances sous forme de petites fiches. Chaque fiche parle d'un sujet, et les fiches sont reliées entre elles, comme les pages de Wikipédia.
L'idée vient d'Andrej Karpathy, cofondateur d'OpenAI et ancien directeur de l'IA chez Tesla. Début avril 2026, il publie sur X la recette de son système (un simple gist en Markdown) et c'est l'emballement immédiat. Son argument massue : son propre wiki de recherche, écrit et entretenu par l'IA, a atteint une centaine d'articles et 400 000 mots (plus long que la plupart des thèses de doctorat) sans qu'il en rédige une seule ligne lui-même.
Le mot important, c'est garder. D'habitude, tu discutes avec une IA et tout part à la poubelle dès que tu fermes la fenêtre. Ici, c'est l'inverse. Chaque chose que tu lui apprends reste, s'ajoute aux autres, et enrichit le tout.
Le truc à retenir : ton IA ne se contente plus de répondre, elle construit une vraie mémoire qui t'appartient.
NotebookLM, les Claude Projects, les custom GPTs : tous marchent un peu pareil. C'est le principe du RAG : on découpe tes documents en petits morceaux, et à chaque question l'IA en repêche quelques-uns pour bricoler une réponse sur le moment. Puis elle oublie.
Le souci, c'est ce découpage. Comme le résume Karpathy, ces morceaux « perdent le contexte qui les entoure » : l'IA redécouvre ton sujet de zéro à chaque question, à partir de fragments.
Le deuxième cerveau fait l'inverse. L'IA écrit ses fiches une fois (des résumés complets, pas des fragments) et les garde. À la question suivante, elle relit ses propres fiches au lieu de tout recommencer. C'est la différence entre relire un livre entier à chaque question et consulter tes notes.
Le système tient sur trois couches qui ne jouent pas le même rôle. C'est cette séparation qui le rend solide.
| Couche | Ce qu'il y a dedans | Ce que fait l'IA |
|---|---|---|
| 1. raw/ | Tes sources brutes : articles, PDF, transcripts | Elle lit, mais ne modifie jamais |
| 2. wiki/ | Les fiches générées, reliées entre elles | Elle en est l'unique auteur |
| 3. CLAUDE.md | Le schéma et les règles du système | Elle le suit à chaque session |
La couche raw/, c'est ta source de vérité immuable. Tu y déposes tout en vrac (à la main ou via le Web Clipper, qui range ses captures dans Clippings/), et l'IA ne fait que lire : elle n'a pas le droit d'y toucher. Les images vont dans raw/assets/.
La couche wiki/, c'est le cerveau. C'est là que l'IA écrit, et elle seule. Voici à quoi ressemble la vraie arborescence de mon coffre :
├── CLAUDE.md ← le schéma, chargé à chaque session
├── raw/ ← sources brutes, IMMUABLES
│ └── assets/ ← images locales
└── wiki/
├── index.md ← le catalogue de tout le wiki
├── log.md ← le journal chronologique (append-only)
├── apercu.md ← la synthèse vivante de l'ensemble
├── _templates/ ← les gabarits de pages
├── sources/ ← un résumé par source ingérée
├── entites/ ← personnes, organisations, produits…
├── concepts/ ← idées, théories, méthodes
└── sujets/ ← thèmes transversaux (synthèses multi-sources)Le wiki/ n'est pas un tas de notes en vrac : chaque fiche a un type. Une source résume un document précis, une entité décrit une personne ou un outil, un concept une idée, un sujet une synthèse qui croise plusieurs sources. Les _templates/ garantissent que toutes les fiches d'un même type ont la même tête, et trois registres tiennent l'ensemble cohérent :
La couche CLAUDE.md, enfin, c'est le mode d'emploi de l'IA. Il définit qui fait quoi (toi tu décides et lis, l'IA écrit), comment nommer les fiches, quel frontmatter mettre selon le type, et des règles d'or : ne jamais inventer, toujours citer ses sources, enrichir une fiche plutôt que l'écraser, et relier généreusement. Les fiches se citent entre elles avec des wikilinks [[Titre de la page]], c'est ce qui tisse le réseau visible dans le graph view.
Obsidian est à la fois un éditeur Markdown et une application de base de connaissances personnelle qui te permet de prendre des notes et de les connecter entre elles pour créer ce « deuxième cerveau ».
| Outil traditionnel | Obsidian |
|---|---|
| Notes en silo (Word, Google Docs) | Notes connectées avec des liens [[ ]] |
| Données dans le cloud | Fichiers locaux .md (tu gardes le contrôle) |
| Recherche par mots-clés | Navigation par connexions + graph view |
| Format propriétaire | Markdown universel (portable, durable) |
Concrètement, trois choses le rendent parfait pour notre cas.
1. Tout reste chez toi. Des fichiers locaux, pas un cloud qui peut fermer. Ton cerveau t'appartient.
2. Il dessine une carte de tes idées. Le graph view relie tes notes entre elles et tu vois ta connaissance prendre forme.
3. Claude adore ce format. Le Markdown est un format texte simple que Claude maîtrise à la perfection.
Ça marche aussi bien sur Windows que sur Mac. Suis le guide.
Va sur le site officiel d'Obsidian, télécharge-le, installe-le, lance-le.
Crée ensuite un coffre (un vault dans Obsidian), c'est juste le dossier qui va contenir tes notes. Appelle-le par exemple veille-ia et choisis où le ranger. Petit conseil : passe en mode sombre, c'est plus reposant pour les yeux.
Ouvre un terminal dans le dossier de ton coffre, puis lance Claude Code. C'est important : Claude doit démarrer pile dans ce dossier, sinon il ne pourra pas lire ni écrire tes fiches.
cd ~/chemin/vers/ma-veille
claudeVa chercher la structure de départ dans le gist d'Andrej Karpathy, copie-la, et colle-la dans Claude avec une consigne comme celle-ci :
À partir de cette structure, tu es maintenant mon agent de deuxième cerveau. Crée le fichier de règles CLAUDE.md, prépare le fichier d'index et le journal, range les dossiers proprement, et montre-moi comment ajouter ma première source.
Claude va créer tout seul les dossiers et les fichiers de base. Tu n'as rien à coder. Tu pourras ajuster le fichier de règles plus tard pour l'adapter à tes besoins.
C'est là que ça devient vraiment pratique. Tu vas créer quatre petits raccourcis que tu déclenches avec un slash. Leur contenu se copie depuis mon repo GitHub (dossier .claude/commands/).
Pour éviter de copier-coller des articles à la main, installe l'extension Obsidian Web Clipper (sur Chrome ou Firefox).
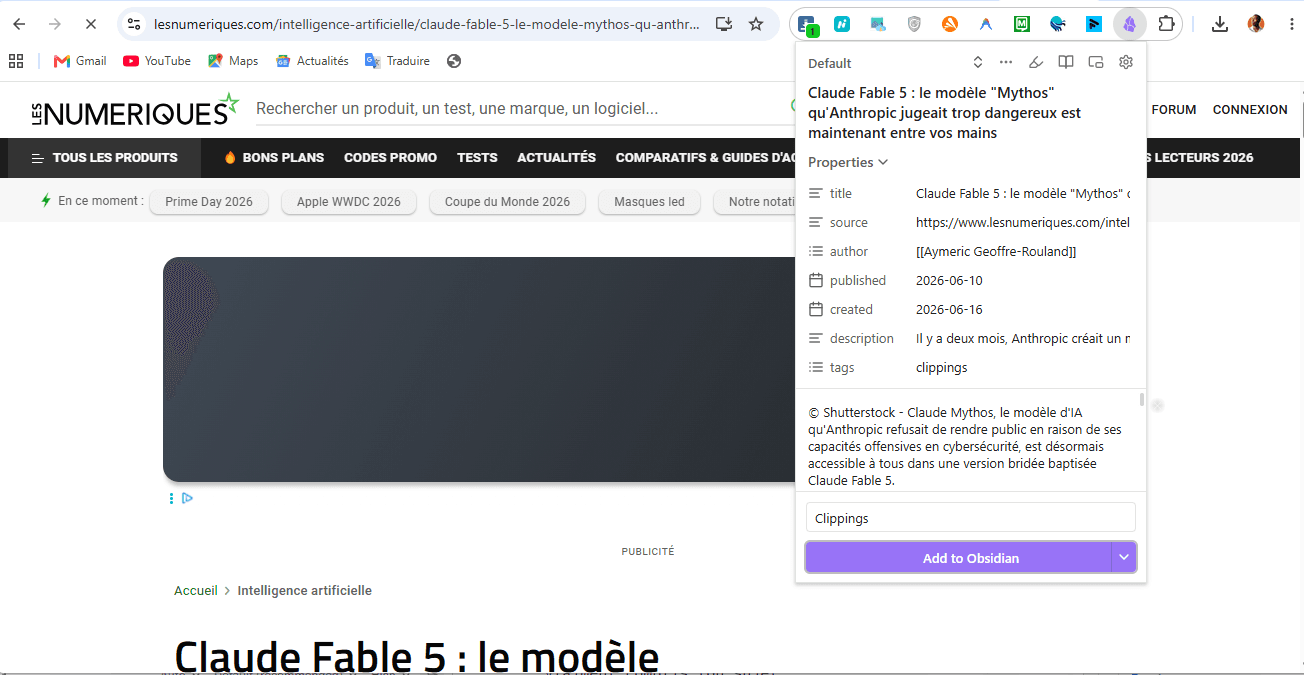
Tu tombes sur un bon article ? Un clic, et l'extension le transforme en fiche propre, rangée directement dans Obsidian. Mets ces captures dans ton dossier fourre-tout (raw/), et laisse Claude trier ensuite.
Une fois tout en place, ta routine tient en trois gestes.
1. Tu déposes des sources dans ton dossier fourre-tout, à la main ou avec le Web Clipper.
2. Tu lances /ingest. Claude lit tes sources et en fait des fiches. Le plus cool : il vérifie ce qui existe déjà et relie les nouvelles infos aux anciennes, au lieu de tout dupliquer.
3. Tu poses tes questions avec /query. Par exemple : "Résume-moi ce qu'on a vu sur tel sujet." Claude répond depuis ton cerveau, et chaque échange peut encore l'enrichir.
De temps en temps, un petit /lint pour vérifier que tout est en ordre, et c'est tout. Le cerveau s'entretient quasiment tout seul.
C'est le moment satisfaisant. Ouvre le graph view dans Obsidian et regarde.
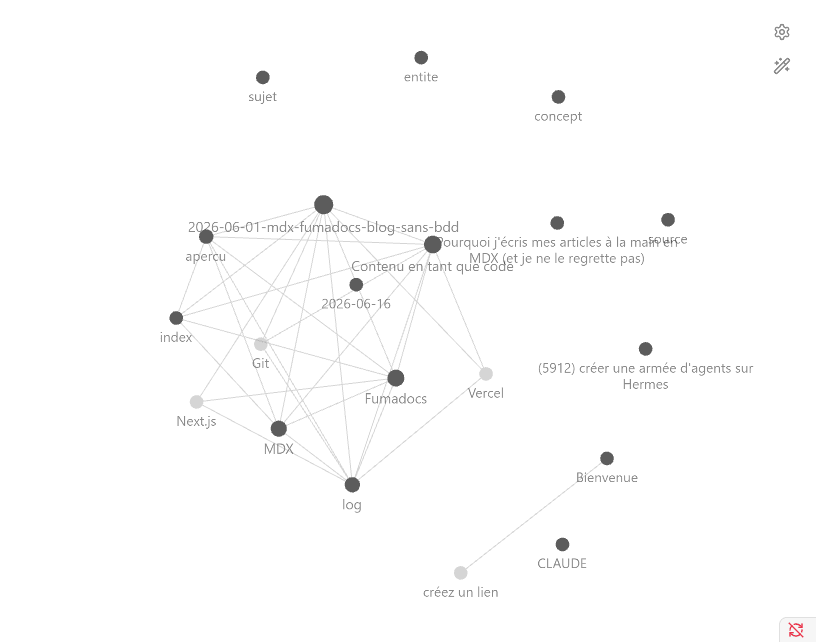
Chaque fiche est un point, relié aux sujets proches par des fils. Tu vois comment tout se connecte : un outil rattaché à son créateur, un sujet lié à un autre, tes résumés qui rassemblent plusieurs sources. Plus tu ajoutes de connaissances, plus la carte grandit et plus les liens apparaissent.
Voici l'essentiel en version courte :
Ce qui rend cette méthode géniale, c'est qu'elle transforme une galère de tous les jours (l'IA qui oublie) en quelque chose qui prend de la valeur avec le temps. Au lieu de repartir de zéro à chaque fois, tu construis un truc qui grossit jour après jour.
Tu as tout pour commencer. Démarre petit : un coffre, deux ou trois articles, les quatre raccourcis. Puis laisse-le grandir. Dans un mois, tu ne pourras plus t'en passer.